Multi-Stage Offensive Operations with Mythic
Introduction
There seems to be a belief amongst some red teamers I have spoken to that for an operation to be “OPSEC sound” or successful for any length of time, the C2 infrastructure must be as inconvenient to use as possible. Fortunately for us, this is not the case, and I hope to prove it to you today.
I believe that Mythic, or something like it, is the future of offensive operations. The primary goal of this blog post is to cover a specific Mythic use case, but I also hope you can see why a modular toolkit such as this could be so valuable for your engagements.
So What is Mythic?
Mythic is a “collaborative, multi-platform, red teaming framework” from Cody Thomas. You may be thinking, “so this is just another open-source C2 framework, right?” While technically not wrong, Mythic is also much more than that. In addition to the characteristics shared by most frameworks, Mythic offers the following features.
- Highly customizable build environments for existing or newly developed agents.
- Interchangeable network profiles that are independent of the core server.
- A modular design to encourage the development of new agents and network profiles.
For more information on what makes this tool unique, I encourage you to read the official introduction, available here.
Background Information
There are many ways to conduct red team engagements, some better than others. The setup I’m describing isn’t intended to be optimal, only to serve as a proof-of-concept.
Typically, I use three or four “stages” of malware on an operation:
- Stage-0 shellcode loader
- Stage_1 reconnaissance implant
- Fully-featured C2 agent, also known as a stage_2 payload
- Minimal implant for long-haul persistence
This is not something I came up with or even unique to BHIS engagements. Current best practice recommends that stage_1, stage_2, and long-haul persistence use different C2 frameworks entirely, with separate infrastructure and network profiles. I agree with this, but the implementations I’ve seen are clunky at best.
The most common scenario described to me looks something like this:
A public shellcode loader such as ScareCrow is used to start a “Stage_1” payload (I put this in quotes because this first implant is usually just a fully-featured C2 agent and is considered safer because it isn’t Cobalt Strike). This payload might be managed from a CLI, Web UI, or desktop GUI.
This agent is used until the operator finds a missing feature that Cobalt Strike has. The current payload is used to establish a Cobalt Strike Beacon, and the operation continues.
This configuration will work but is inefficient for multiple reasons. First, it depends on security products and staff focusing their detections on Cobalt Strike signatures and neglecting similar indicators in open-source tools. While somewhat true in my experience, this could change at any moment and is a dangerous assumption. Additionally, this configuration requires an operator to understand two different C2 frameworks and use two separate interfaces for managing implants. This is even more annoying when multiple operators need to agree on two frameworks and maintain access and credentials to both interfaces.
These issues could be solved by developing a new C2 framework with two different implants or by creating a minimal implant for initial recon compatible with an existing framework. This is precisely where something like Mythic fits in perfectly. Mythic encourages agent development with ample documentation and multiple models in various programming languages. So even if you have limited development resources, you could start by building implants based on public examples.
Today’s Topic: Stage_1 and Stage_2 Implants in Mythic
Terraform is an open-source tool for creating infrastructure by defining it in configuration files. The rest of this post will refer to a Terraform configuration available on my GitHub.
You might be thinking, “It’s great that you have two different payload types, but they’re calling back to the same server! Wouldn’t it be easy for the security team to find one implant and stop both by blocking that IP address or domain name?” It would be easy if these two implants called back to the same place, yes. However, with the magic of DevOps, we can quickly spin up separate network infrastructures for each implant.
While we could build redirectors with Apache or Nginx on separate cloud platforms and register domain names for each, we can instead use CDNs to simplify the deployment and provide semi-reputable domain names. For example, the Azure CDN allows us to create a unique subdomain of azureedge.net while AWS CloudFront generates a random subdomain of cloudfront.net.
The final configuration will look something like this:
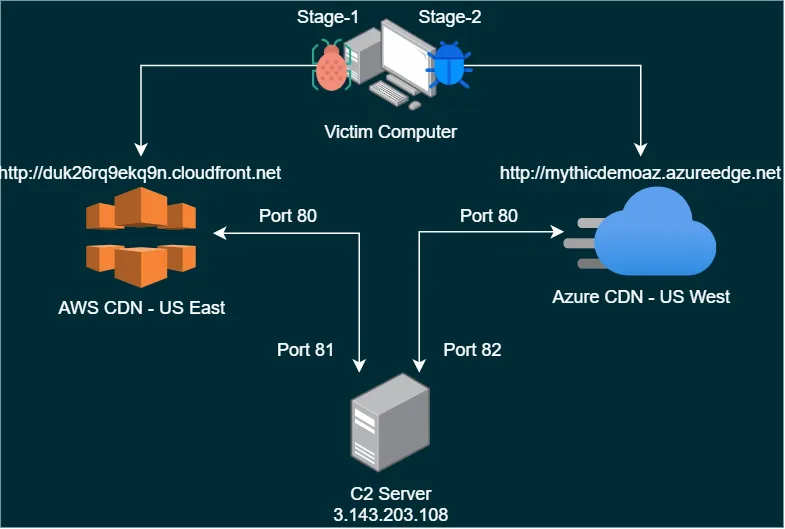
As you can see, the first stage will be using AWS CloudFront, and the second stage will use Azure CDN. Azure allows you to specify a subdomain name for CDN endpoints. I will use “mythicdemoaz” for this example, but you should key this value to a specific social engineering ruse.
As this is not meant to be a post on payload development, Atlas will be used as the Stage_1 payload, and Apollo will be used as Stage_2 in this scenario.
Terraform Configuration
This deployment will generate two Mythic agents in the “payloads” directory. Therefore, Windows users will need to add a Defender exclusion for the folder before proceeding.
A few variables need to be configured in Terraform to start the example deployment I linked earlier.
- Provide a Mythic username and password for logging in to the web UI. The variables for this are “mythic_user” and “mythic_password”, respectively.
- Modify the “public_key_path” and “private_key_path” to contain the paths for your SSH public and private keys.
- Add any number of public IPs to the “aws_ip_allowlist” variable to allow yourself access to the Mythic web UI once it is deployed.
Configuring Azure CDN
Setting up Azure CDN is straightforward, as it only requires us to turn it on and point to an existing IP or domain.
Install the Azure CLI tool and run `az login“ in a command prompt. Once configured, create a subscription in Azure and copy the subscription ID into the Terraform variables file. Be sure to change the “azurecdn_name” variable to contain the desired subdomain name for the CDN endpoint.
Configuring AWS CloudFront CDN
AWS CloudFront is different because it cannot target an EC2 instance directly. Instead, it is first required to configure an Elastic Load Balancer and then point the CDN endpoint at that device.
Create an AWS credential file for Terraform by installing the AWS CLI tool and running aws configure in a command prompt. Once configured, fill in the “aws_cred_file” Terraform variable with the path to the AWS credential file. This is typically located at ~/.aws/credentials.
Finally, apply the Terraform configuration with terraform init followed by terraform apply -auto-approve. Applying the configuration can take several minutes and should produce the following output:
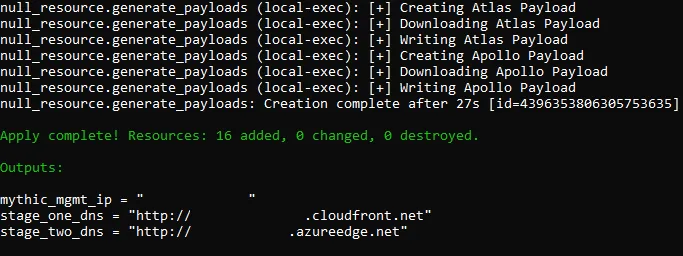
Operation Pre-Checks
The Terraform deployment will create a Mythic server, configure the HTTP profile, and generate both implants, storing the output executables in the payloads directory. Any configuration should be tested before use on an engagement to ensure it works as expected and won’t leak any data to security appliances and professionals, though.
Each implant can be statically and dynamically analyzed to ensure no information leaks are present. In this example, my deployment was assigned the following values.
- mythic_mgmt_ip = “3.143.203.108”
- stage_one_dns = “http://duk26rq9ekq9n.cloudfront.net”
- stage_two_dns = “http://mythicdemoaz.azureedge.net”
Static Analysis
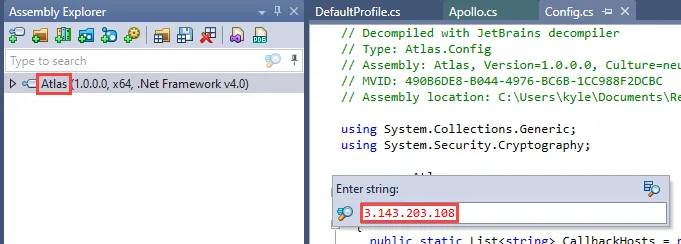
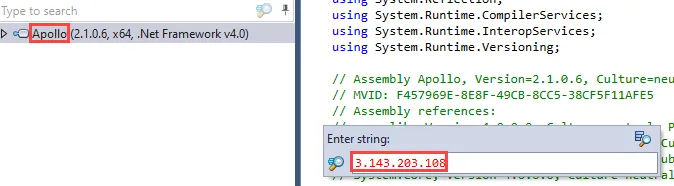
Right away, we can open each of the implants in a .NET decompiler to search for the IP address and port of our backend C2 server. I recommend using dotPeek for this step as it has the best search function of the tools I’ve tried. First, I will search for an expected string, the CDN hostname, in each implant.
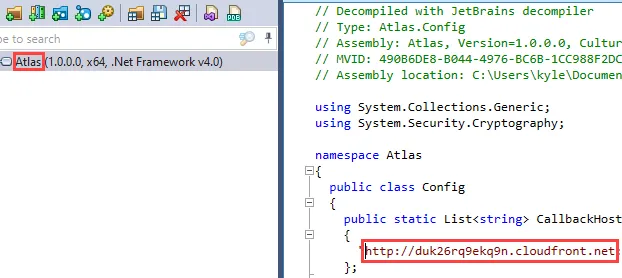
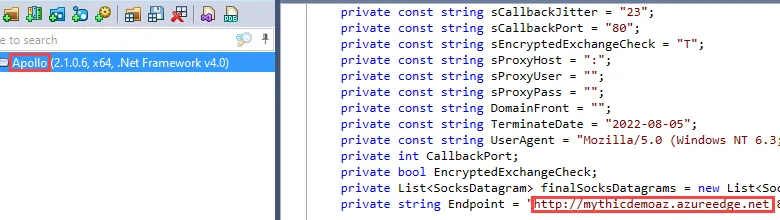
After this has been confirmed, I will search for the IP address of the backend Mythic server to verify it is not in the binary.
Dynamic Analysis
Once we’ve verified that the backend IP address is not present in the implants, execute the payloads and use Wireshark to analyze network traffic.
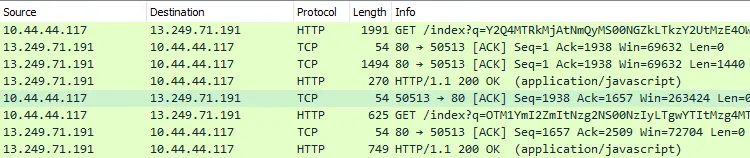
The DNS queries of each implant can be observed first.


In the following screenshots, the compromised host (10.44.44.117) using the Stage_1 implant is communicating over HTTP with the Atlas/CloudFront service (13.249.71.191).”
Similarly, the Stage_2 implant is communicating with the Apollo/Azure service (13.107.246.57).

Finally, we can use Wireshark’s “Find Packet” function to quickly search for the Mythic backend server IP address in all packets.
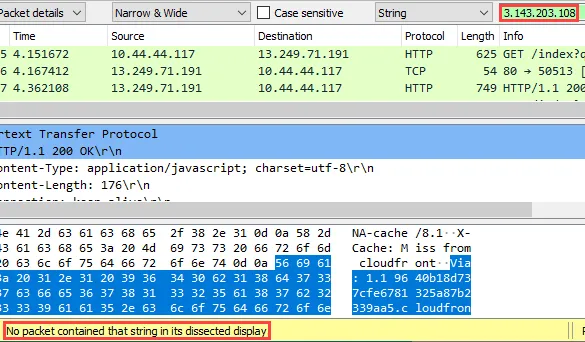
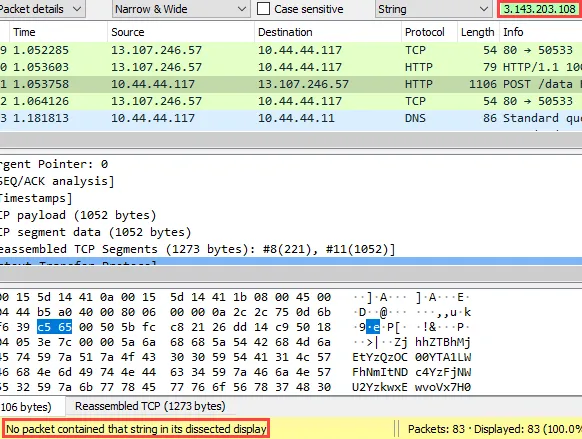
Combining these static and dynamic techniques gives us reasonable confidence that the Mythic server IP address is not discoverable.
Closing Thoughts
There are many ways this configuration could be modified for different situations, but I would recommend starting with the following:
- In this example, SSL was not enabled to simplify traffic analysis and deployment. Encrypting traffic with these CDNs, however, is straightforward and should be utilized in an actual engagement.
- This is the most basic configuration which obfuscates where the two payload types are calling back to. However, there may be situations where you want additional layers between a target environment and your C2 server for added resiliency.
I hope the walkthrough of this use case provides a new perspective on Mythic and how it might be helpful to your upcoming operations. Feel free to contact me with any other questions or comments on Twitter @kyleavery_.
Credits
- None of this would be possible without the Mythic development team, specifically the work of Cody Thomas.
- Much of the Terraform configuration was stolen from Ralph May’s work.